From One Branch to Many: How Smart Systems Scale Without Chaos
Overview
Scaling a clinic into a multi-site network is supposed to be a growth story — more patients, more revenue, more impact.
Too often it becomes a headache: duplicated workflows, fractured records, angry patients, and exploding admin costs. The difference between scaling with success and scaling into chaos is systems: interoperability, governance, repeatable processes, and targeted AI that stitches everything together.
This article explains how to scale from one branch to many without chaos, backing recommendations with public studies and real health-system examples, and ending with a practical rollout playbook you can use next week.
Why scaling fails (quickly)
Three common failure modes:
Data silos multiply. Each new site tends to add its own workflows, spreadsheets, and shadow systems, multiplying re-typing and errors. Interoperability isn’t a “nice to have” — it’s the glue that prevents the mess. HIMSS finds that leaders building interoperability reduce data silos and improve quality of care. himss.org
Clinician friction. Doctors and nurses resist tools that slow them down. Big, disruptive rollouts that change clinician workflows without showing quick wins lead to abandonment and workarounds. Kaiser’s long EMR transition experience shows that user buy-in and staged rollouts are essential. PMC+1
No repeatable playbook. A one-off custom integration for site 1 rarely scales to site 10. Without standards, each branch becomes another unique integration project — cost and complexity explode. Research on EHR interoperability links better data flows to measurable improvements in safety and quality; the reverse is true when interoperability is weak. PMC
What successful systems do differently — lessons from large health systems
Large systems that scaled well share common patterns:
Central governance + local autonomy. Organizations like Kaiser and Cleveland Clinic set enterprise standards (data models, workflows, security) but allow local sites to tailor less critical workflows. Cleveland Clinic’s digital strategy emphasizes aligning digital initiatives to clinical mission and using enterprise platforms for shared capabilities. Cleveland Clinic+1
Standards-first interoperability. Use FHIR/HL7, vetted EMPI/MPIs and a dedicated interoperability layer (not ad hoc point-to-point connectors). HIMSS guidance on interoperability describes levels and practical steps for connecting systems across organizations. himss.org+1
Pilot → prove → scale. Start with a high-impact pilot (scheduling, claims, or bed management), prove measurable ROI, then replicate the pattern across sites. Case studies show pilots deliver visible wins that justify broader rollouts. Momentum
Automate operational repeatability. Credentialing, billing, and onboarding are common scaling bottlenecks. Automating these central services prevents admin costs from scaling with headcount. (Playbooks for credentialing and automated workflows highlight large savings and faster scale.) withassured.com
The role of AI: not a silver bullet — a strategic amplifier
AI isn’t the destination; it’s an accelerator when used to standardize and automate the right problems.
Practical AI roles that help scale without chaos:
Data normalization & master patient index (EMPI) automation. AI can match and merge duplicate records across sites so a patient has one canonical record across the network. This prevents duplicate tests and billing errors. Studies on interoperability show major safety and quality wins once records are unified. PMC
Workflow automation for repeatable tasks. Scheduling, reminders (WhatsApp/SMS), and claims pre-validation are prime AI candidates. These free staff and ensure uniform processes across branches.
Operational dashboards and prediction. AI powered dashboards that surface bed bottlenecks, staff overload, and claim rejection risks let central teams triage problems before they spread.
Low-risk pilots with high ROI. Billing/RCM automation and no-show prediction typically return value fastest — ideal pilots to prove the model and fund expansion. Industry reports show revenue-cycle and scheduling pilots often pay back quickly. Momentum+1
Evidence: interoperability and scaling improve outcomes (selected references)
A systematic study found EHR interoperability improves aspects of patient safety and care quality in high-income settings — showing measurable benefits once data works across locations. PMC
HIMSS’ recent work on interoperability offers practical approaches and frameworks for leaders trying to connect systems at scale. himss.org+1
Kaiser and Cleveland Clinic case studies show that enterprise approaches — not piecemeal projects — are necessary for sustainable scale and clinical alignment. commonwealthfund.org+1
(References above are the primary sources used in this article — see citation tags.)
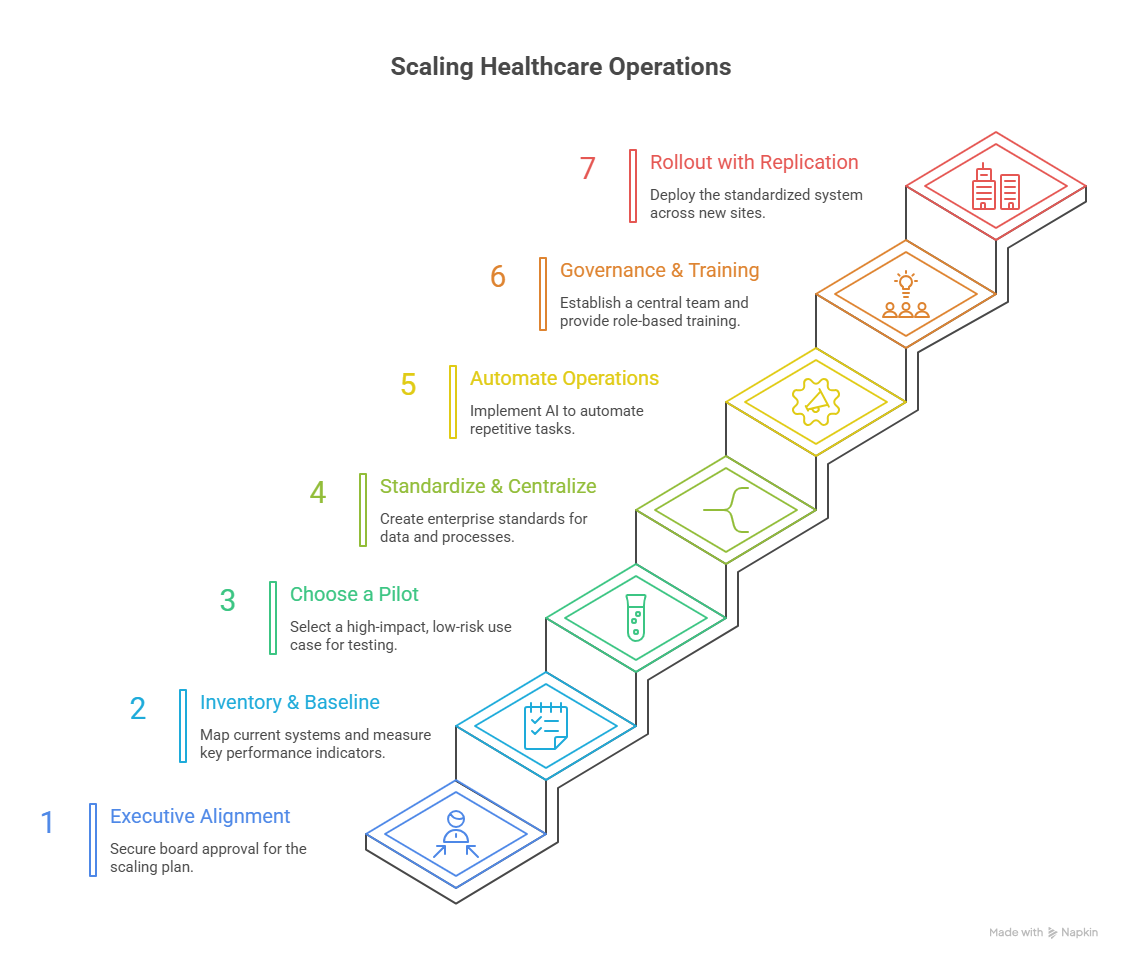
A practical 6-step playbook to scale without chaos
Below is a concise, actionable playbook. Each step is designed to be measurable and repeatable across branches.
Step 0 — Executive alignment (Day 0)
Get the board/owner to sign a one-page charter:
Target outcomes (reduced wait time, fewer denials, centralized dashboards)
Budget envelope for pilot + scale
Decision trigger criteria for phase-2 scale (e.g., 20% reduction in denials or X hours saved)
Why: Prevents scope creep and political stalls later.
Step 1 — Inventory & baseline (Week 1–2)
Map current systems, interfaces, and processes across the existing site(s): EMR, lab, radiology, billing, scheduling, third-party apps. Measure baseline KPIs: check-in time, claim rejection rate, staff admin hours, no-show rate, days in AR.
Why: You can’t improve what you don’t measure.
Step 2 — Choose a 3-week pilot (Week 3–6)
Pick a high-impact, low-risk use case that will be easy to measure and replicate. Good candidates:
Claims pre-validation to cut denials (RCM)
WhatsApp booking + reminders to cut no-shows
Bed/triage dashboard to reduce ER turnaround
Deploy a plug-and-play AI layer that runs alongside the EMR (no rip-and-replace). Measure weekly.
Why: Short pilots prove value quickly and build trust.
Step 3 — Standardize & centralize (Week 6–12)
Create enterprise standards for data (FHIR profiles, code sets), logging, and security. Deploy a central EMPI/ID service so each patient has one canonical record across sites. Centralize credentialing, payer onboarding, and template libraries (order sets, note templates).
Why: Standards make replication simple.
Step 4 — Automate operations (Months 3–6)
Move repetitive admin tasks to automation: scheduling, reminders, claims validation, and credential renewals. Use AI for normalization (addresses, name variants) to avoid duplicate creation across branches.
Why: Keeps admin costs from scaling linearly with sites.
Step 5 — Governance & training (Ongoing)
Create a small central ops team that runs onboarding, vendor management, security audits, and the AI governance checklist (model versioning, explainability, audit logs). Provide role-based training and a 7-day quick start for new site staff.
Why: Sustains quality and avoids site drift.
Step 6 — Rollout with a replication pack (Months 6–18)
For each new site: use the same project checklist (data mapping template, integration adapter, staff training pack, pilot KPIs). Expect a 2–4 week technical go-live and a 6–8 week operational stabilization period.
Why: Repeatability reduces time and cost per site.
Scaling Healthcare Operations
Practical checklist (one-page)
Baseline KPIs collected (check-in time, denials, staff hours)
Enterprise EMPI/ID strategy in place
Interoperability layer using FHIR/HL7 standards deployed
Pilot use case selected and ROI targets set
Human-in-the-loop rules defined for AI decisions
Central ops & governance team formed
Site replication pack created (integration scripts, training, KPI dashboard)
Common pitfalls and how to avoid them
Pitfall: Trying to “fix everything” on day one. Fix: Prioritize high-impact, repeatable pilots and scale the pattern.
Pitfall: Building bespoke connectors for every site. Fix: Use an interoperability layer and standard APIs, not point-to-point integrations. HIMSS guidance supports this approach. himss.org
Pitfall: Ignoring clinician workflows. Fix: Involve clinicians in design, measure time-saved, and reward local champions (Kaiser lessons reinforce this). international.kaiserpermanente.org
Pitfall: No governance for AI/model drift. Fix: Version models, log decisions, and schedule quarterly model reviews.
Quick wins you can deploy in 8–12 weeks
WhatsApp booking + reminders for one specialty to cut no-shows (localization for language and culture).
Claims pre-validator that pre-checks schema, membership, and codes before NPHIES/payer submission.
Bed-board dashboard that aggregates ER, inpatient, and OR statuses for faster transfers.
EMPI cleanup sprint using probabilistic matching to reduce duplicate charts by >80% in 3 months.
Conclusion
A plan is a must to avoid scaling chaos, but more than that businesses need to invest in a capable tech partner.
-min.png)